PMSA003I and Embedded Serialization
The PMSA003 is a small (sub $20) particulate matter sensor. As with most PM sensors, this module uses a fan and a laser to detect the size and counts of particulates in the air.
As I am using the I2C version for current project, I needed to write the driver for it. When creating the struct, I realized the sensor's data response was in big-endian utilizing both full of half-word uint16_ts. How unfortunate I thought, I am using a little-endian microcontroller and now I will have to meticulously swap these parameters. I carried on, following the datasheet I wrote the following struct:
1#pragma pack(1)
2namespace PMSAIType {
3// Normal response definition from PMSAI
4struct response {
5 uint8_t start1;
6 uint8_t start2;
7 uint16_t frameLength;
8 uint16_t cf_pm1_0;
9 uint16_t cf_pm2_5;
10 uint16_t cf_pm10_0;
11 uint16_t pm1_0;
12 uint16_t pm2_5;
13 uint16_t pm10_0;
14 uint16_t count0_3;
15 uint16_t count0_5;
16 uint16_t count1_0;
17 uint16_t count2_5;
18 uint16_t count5_0;
19 uint16_t count10_0;
20 uint8_t version;
21 uint8_t error;
22 uint16_t check;
23};
24}
25#pragma pack()
NOTE: It is not possible to just cast a byte array into this struct type because of the endianness difference between the response and most microcontrollers.
Great. Now I just need to do a block read of the 32 bytes from the I2C bus; store them in a temporary buffer; and manually load each member, being sure to swap bytes around for multi-byte members.
That idea didn't sound that great to me. This could potentially create issues, as different areas of the code are not directly coupled. So I started looking around for a lightweight solution...
µSer portable serialization library for C++
The µSer project is a standalone header file which generates the exact code I was describing earlier, auto-magically! It achieves this through intelligent compiler defines added around struct definitions and some magical C++17 templating. Thus, the code for serialization and deserialization is directly coupled to the struct definition! 🙂
So for the response struct above, a mere two lines need to be added.
1USER_EXT_ANNOT(PMSAIType::response, uSer::ByteOrder::BE)
2
3USER_EXT_ENUM_MEM(PMSAIType::response, start1, start2, frameLength,
4 cf_pm1_0, cf_pm2_5, cf_pm10_0, pm1_0, pm2_5, pm10_0, count0_3,
5 count0_5, count1_0, count2_5, count5_0, count10_0, version, error, check)
With these lines the preprocessor and compiler can inform the µSer generators with the member definitions of this particular struct. To perform a deserialization, it is now as easy as passing the input data buffer and a response output struct, like so:
1PMSAIType::response localResp = { 0 };
2uSer::deserialize(buf, localResp);
At what cost?
As, I am working on resource limited microcontrollers (in this case a 32KB flash ARM M23), the code size really does matter. That being the case, it is unacceptable if the deserialize function uses 1KB of ROM due to included libraries and subroutines. Likewise, runtime matters too, as that translates to more battery runtime and overall efficiency.
Through binary analysis of the Intel .hex file, I was able to find the following function (I learned later that an easier approach would have been to just look at the *.o object file). I used the NSA's open source software reverse engineering framework Ghidra.
1void FUN_00003a08(undefined4 *param_1, undefined *param_2, undefined4 param_3, undefined *param_4)
2{
3 undefined uVar1;
4
5 *param_4 = *param_2;
6 param_4[1] = param_2[1];
7 *(ushort *)(param_4 + 2) = CONCAT11(param_2[2],param_2[3]);
8 *(ushort *)(param_4 + 4) = CONCAT11(param_2[4],param_2[5]);
9 *(ushort *)(param_4 + 6) = CONCAT11(param_2[6],param_2[7]);
10 *(ushort *)(param_4 + 8) = CONCAT11(param_2[8],param_2[9]);
11 *(ushort *)(param_4 + 10) = CONCAT11(param_2[10],param_2[0xb]);
12 *(ushort *)(param_4 + 0xc) = CONCAT11(param_2[0xc],param_2[0xd]);
13 *(ushort *)(param_4 + 0xe) = CONCAT11(param_2[0xe],param_2[0xf]);
14 *(ushort *)(param_4 + 0x10) = CONCAT11(param_2[0x10],param_2[0x11]);
15 *(ushort *)(param_4 + 0x12) = CONCAT11(param_2[0x12],param_2[0x13]);
16 *(ushort *)(param_4 + 0x14) = CONCAT11(param_2[0x14],param_2[0x15]);
17 *(ushort *)(param_4 + 0x16) = CONCAT11(param_2[0x16],param_2[0x17]);
18 *(ushort *)(param_4 + 0x18) = CONCAT11(param_2[0x18],param_2[0x19]);
19 *(ushort *)(param_4 + 0x1a) = CONCAT11(param_2[0x1a],param_2[0x1b]);
20 param_4[0x1c] = param_2[0x1c];
21 param_4[0x1d] = param_2[0x1d];
22 uVar1 = param_2[0x1f];
23 *(ushort *)(param_4 + 0x1e) = CONCAT11(param_2[0x1e],uVar1);
24 *(undefined **)param_1 = param_2 + 0x20;
25 *(undefined *)(param_1 + 1) = uVar1;
26 return;
27}
As one can see, the decompiled code generated is fairly straightforward. The data buffer is passed in and each member is manually loaded, with special care for multi byte members. Pretty much just how I would have written it myself.
ASM Deep Dive
Let's compare how the C/C++ compiler structured the code, as the function above is fairly repetitive I will only look at one line.
1*(ushort *)(param_4 + 2) = CONCAT11(param_2[2],param_2[3]);
2// which basically says this...
3param_4[2] = (param_2[2] << 8) | param_2[3];
The following 5 lines of assembly perform this exactly, step by step.
1ldrb r4,[r3,#0x2] load byte from address in r3 + 2
2ldrb r1,[r3,#0x3] load byte from address in r3 + 3
3lsl r4,r4,#0x8 left shift r4 by 8
4orr r1,r4 or r4 into r1
5strh r1,[r2,#0x2] store half-word r1 into address in r2 + 2
With the function located lets look at the hex dump. In Ghidra, I was able to determine that the function starts at offset 0x00003a08 (aptly named FUN_00003a08) and continues on to offset 0x00003acc. Through subtraction, it is clear that the function consumes C4 = 196 bytes of ROM. Not too shabby at all.
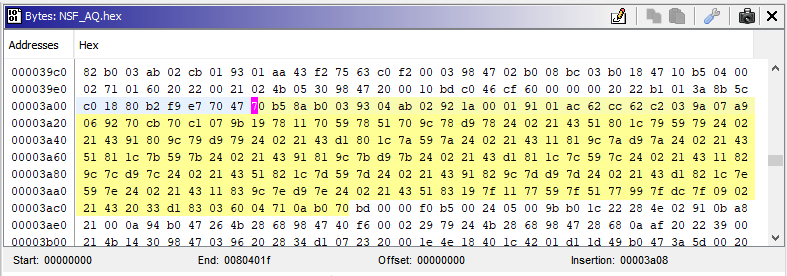
Realistically speaking, the time it would have taken me to write, test and debug the same code would make the potential for savings moot at sub 200 bytes.
I would like to give a shout out to Niklas Gürtler for the great work put into µSer and its amazing documentation.